DMwR-note-01-预测海藻数量(一)

问题描述与目标
描述:有害藻类的高浓度会对河流生态环境造成强大的破坏,所以对有害藻类的数量进行预测对提高河流质量有很重要的意义。
目标:影响藻类繁殖的因素有什么特征。
数据说明
本案例有2个数据集:训练集和测试集
变量说明:
名义变量
- season : 季节
- size : 河流规模
- speed : 流速
数值变量
- mxPH : 最大PH值
- mnO2 : 最小含氧量
- Cl : 平均氯化物含量
- NO3 : 平均硝酸盐含量
- NH4 : 平均氨含量
- oPO4 : 平均正磷酸盐含量
- PO4 : 平均硝酸盐含量
- Chla : 平均叶绿素含量
数据加载到R
本例直接下载”DMwR”包,然后载入R空间,就可以得到一个algae的数据框。
1 | > library("DMwR", lib.loc="e:/R/R-3.1.1/library") |
- 数据框可以看做一种有列名称的矩阵或者表格,它是存储R数据表的一种理想的数据结构。函数head讲显示数据框的前6行。
数据可视化和摘要
探索性数据分析-summary
在没有充分了解数据之前,我们可以首先了解一下数据的统计特性。R中提供了一个非常便利的函数summary,下面我们从探索性数据分析着手进行分析。
1 | > summary(algae) |
- 由结果可知,summary的作用是:
- 名义变量(R中用因子来表示):统计数据中该变量某个值的频数。譬如,季节(season)当中秋季(autumn)出现的次数是40。
- 数值变量:summary为我们提供了均值、中位数、四分位数、极值等一系列的统计信息。譬如,最大的PH值(mxPH)当中,最小值是5.600,最大值是9.700,中位数是8.060,第一个四分位数(1st Qu),即数据排序后25%的地方,是7.700,第三个四分位数(3st Qu),即数据排序后75%的地方,是8.400,还有缺失值(NA)的个数是1.000。
数据分布状况-hist
1 | > hist(algae$mxPH, prob = T) |
plot:
- 该指令绘制变量mxPH的直方图。设置参数pro=T,我们可以得到每个取值区间的概率,如果该参数设置为FALSE或者忽略该参数,它将给出频数。
- 由图中观察,变量mxPH的分布非常接近正态分布,它的值大部分聚集在该均值的周围。我们通过QQ图来检验该变量是否为正态分布。
1 | library("car", lib.loc="e:/R/R-3.1.1/library") |
plot:
- 左图中的曲线是平滑版本的直方图,而在X轴上密密麻麻的小直线就是变量的实际值,利用它我们可以识别出离群点。譬如,小于6的两个奇异点。
- 右图是Q-Q图,图中黑色实线是正态分布的理论分位数,而散点图就是实际变量值的描述。另外,虚线组成的区域就是符合正态分布的95%置信区间的带状图。由图可知,变量有几个小的值明显在95%的置信区间之外,它们不服从正态分布。
数据分布状况的另一种展示-箱型图
百度百科:箱型图
1 | boxplot(algae$oPO4, ylab = "Orthophosphate(oPO4)") |
plot:
lattice版本的箱图-bwplot
条件绘图室依赖于某个特定因子的图形表示。因子是一个取值为有限集合的名义的变量。例如,对于变量size的不同取值,可以绘制变量a1的一组箱图。每个箱图是对应于变量size的某个特定值的水样子集。通过这些箱图可以研究名义变量size如何影响变量a1值的分布。
1 | library(lattice) |
plot: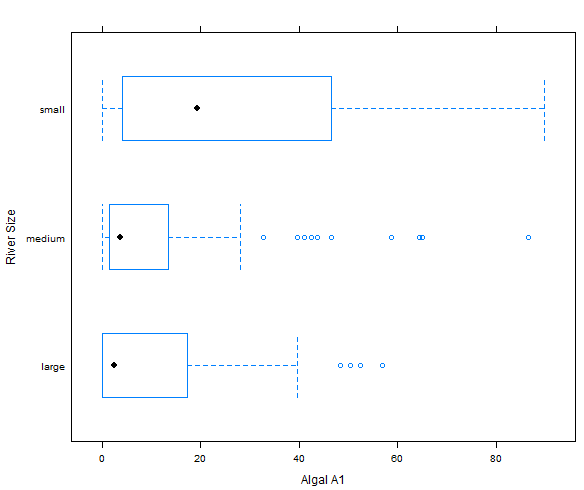
- 由上图可知,在规模较小的河流中,海藻a1的频率较高,这是很有用的信息。
Hmisc版本的箱图-bwplot
分位箱图
1 | library(Hmisc) |
plot: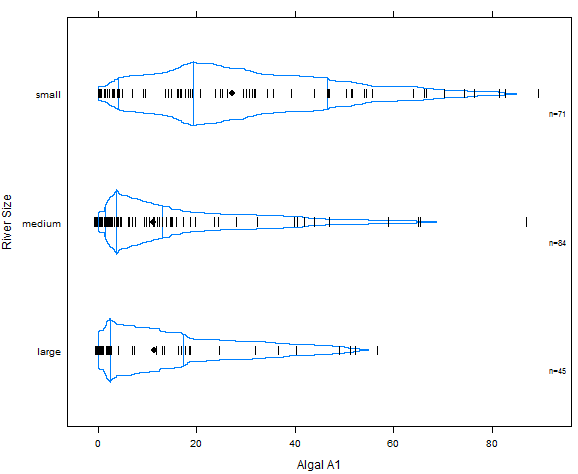
- 图中的点代表均值,而图中的竖线分别代表变量的第一个分位数、中位数和第三个分位数。图中的小竖线代表数据的真实取值,这些值的分布则由分位数图来体现。分位数箱图比上一个箱图提供了更多的信息。
- 我们可以得到以下结论:小型的河流有更高频率的海藻,但我们也观察到小型河流的海藻频率的分布比其他类型的河流频率的分布分散。
Hmisc版本的升级箱图-多个变量
这种类型的条件绘图不局限于名义变量,也不局限于单个因子。只要先把连续变量“离散化”,也同样可以进行条件绘图。下面给出一个两个因子条件绘图的例子。考虑变量a3在给定变量season和变量mnO2下的条件绘图,变量mnO2是一个连续变量,绘图代码如下所示:
1 | minO2 <- equal.count(na.omit(algae$mnO2),number=4, overlap=1/5) |
plot:
- 第一行调用equal.count()对连续变量mnO2离散化,把该变量转换为因子类型。参数number设置需要的区间个数,参数overlap设置两个区间之间的靠近边界的重合(这意味着某些观测值将被分配到相邻的区间中)。每个区间的观测值的个数相等。注意,变量algae$mnO2中含有NA值,所以上面的指令中没有直接应用该变量,否则会导致其后的绘图函数出错。函数na.omit()可以用来剔除向量中的任何NA值。
- 第二行调用绘图函数stripplot(),该函数是lattice包中的一个绘图函数,它根据另一个变量(这里是season)把变量的实际值绘制到不同的图形。这些区间按照从左到右,从下到上的顺序排列。即与左下方的图形相对应的是较小的mnO2值。变量mnO2中的NA值也会对图形的绘制产生影响。不能像绘制上图中那样直接应用参数data=algae,而应该先剔除水样中变量mnO2含有NA值才行。
- 所以,下一次的笔记是针对缺失值的处理的。
后记
本次博文是根据《数据挖掘与R语言(Luis Torgo著)》这本书的内容而写的笔记,本博文中所涉及的内容版权均归原作者所有。
- 下节讨论的主题是数据缺失值的处理。
- 本文标题:DMwR-note-01-预测海藻数量(一)
- 创建时间:2014-10-23 15:53:18
- 本文链接:2014/10/23/技能-修行-进步-R语言/DMwR-note-01-预测海藻数量(一)/
- 版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
评论